
This blog is a result of my experiments with Semantic Kernel SDK (from Microsoft) in creating AI Agents using Python programming and Open Source Generative AI models from HuggingFace.
Being from Microsoft, Semantic Kernel has more functionality for development in C# langauge and more examples using Open AI and Azure Open AI models.
A lot of material on this blog is from the original Microsoft Documentation and Github repository of Semantic Kernel (Python version only and Open Source LLMs only, because I love opensource and I speak Python).
Lets begin.
What is an agent?
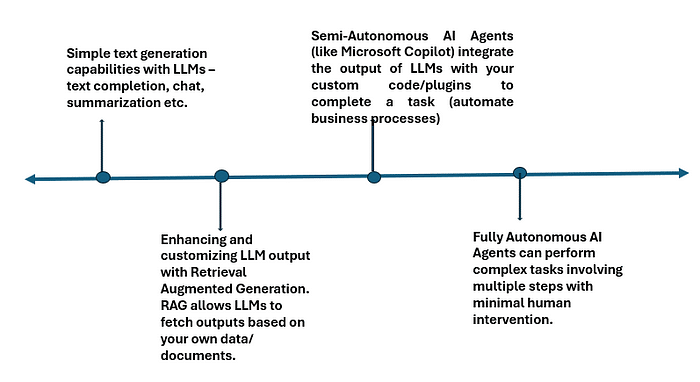
An AI agent we are speaking about here is a computer program that uses artificial intelligence techniques to automate your tasks involving use of natural language processing, computer vision, and audio processing.
E.g., we can build a simple AI agent that answers your questions based on your organisation’s data and documents, or we can build a helpful agent that helps you write your emails by suggesting correct spellings or the words to use, or we can build a complex AI agent that can create the email content and automatically send it to the designated recipients for you. The last one, needs to generate context specific content for your emails.
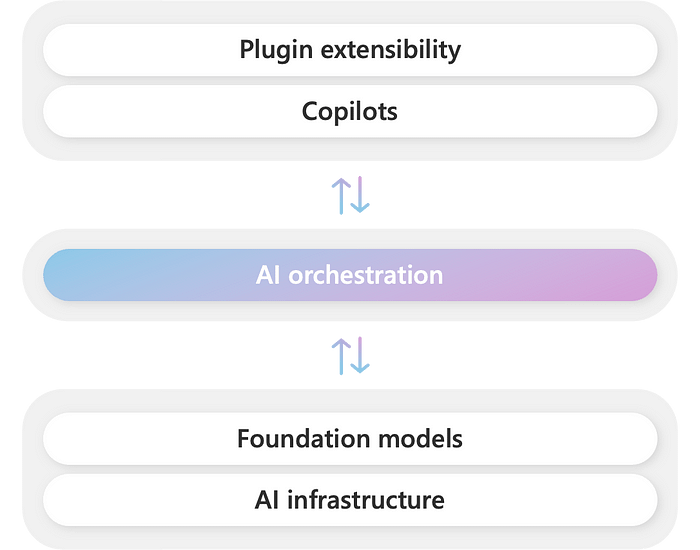
An agent is made up of three core building blocks:
- plugins
- planners, and
- its persona.
These building blocks allow an agent to retrieve information from the user or other systems, plan how to use that information, and use that information to respond to a user or perform an action.
For example, an agent (like Microsoft Copilot) that helps a user write and send an email. After getting instructions from a user, this agent generates a plan using available plugins to complete the task.
This plan would include steps like…
- Get the user’s email address and name
- Get the email address of the recipient
- Get the topic of the email
- Generate the subject and body of the email
- Review the email with the user
- Send the email
1. Plugins: giving your agent skills
- To generate a plan, the agent needs the certain capabilities (skills).
- You can give these capabilities to your agent through plugins (your custom code written in a programming langauge.)
- E.g., You can write custom plugins to sends emails, retrieve information from a database, asks for help, or saves and retrieve memories from previous conversations. You can also create plugins using APIs.
2. Planners: giving guidance to your agent
- Planners are special prompts that allow an agent to generate a plan to complete a task by using plugins and integrating their output with other parts of the agent. The simplest planners are just a single prompt that helps the agent use function calling to complete a task.
- Planners are task specific specialized plugins. E.g., you may create an AuthorEmailPlanner that asks the agent to “brainstorm the steps necessary to write an email before calling the necessary functions.” In this planner, we can pass in the email topic and the recipient of the email so the planner can generate a plan to write an email. For more advanced, code-based planners, we can ask an LLM to generate code that can be executed to complete a task.
3. Persona: giving your agent a personality
- The persona is a prompt that is used to influence how the agent responds to user inputs. It is often called a “meta prompt” or “instruction”.
- You can use persona to set a personality, tone or style for your agent. E.g., a friendly agent, a sarcastic agent, a helpful agent.
- You can also use the persona to influence how the agent responds to certain situations. E.g., you can use the persona to tell the agent to ask for help if it doesn’t know what to do. Or to be more verbose when it is explaining something to a user.
- You can use personal to make sure the agent retrieves all the informaion it needs before completing a task, this would encourage the persona to als more questions to perform the task better. This can be done by passing in a system prompt into a ChatHistory object that contains the persona. This ChatHistory object will then be used whenever we make a request to the agent so that the agent is aware of its persona and all the previous conversations it has had with the user.
Semantic Kernel SDK
This section contains information from the original Semantic Kernel Documentation page.
- Semantic Kernel is a light weight open-source SDK from Microsoft for building your AI agents that can integrate generative AI models and your own code (plugins) to perform useful tasks for you.
- i.e., Semantic Kernel is a framework that allows you to take responses from AI models and use them to call existing code to automate business processes or create interesting applications. As we know, the models like GPT, Gemini, Llamma generate text and images. Your own functions or plugins can use the generated content to automate business processes for your.
- At present you can use semantic kernel to integrate LLMs from OpenAI, Azure OpenAI and Open Source models from HuggingFace with your own code written in C#, Java or Python.
- Semantic kernel provides the orchestration layer that enables the gen AI models to call your own functions or plugins. With Semantic Kernel you can easily describe your existing code (functions or plugins) to AI models, these models can then request the appropriate function (plugin) to be called as required to perform a business function. Semantic Kernel translates the model’s response into a call to your code.
- Semantic kernel’s extensible programming model combines natural language semantic functions, traditional code native functions, and embeddings-based memory, enabling you to build new applications. You can augment your applications with prompt engineering, prompt chaining, retrieval-augmented generation, contextual and long-term vectorized memory, embeddings, summarization, zero or few-shot learning, semantic indexing, recursive reasoning, intelligent planning, and access to external knowledge stores and proprietary data.
Let us build our own AI agent using Python, GPT2 from HuggingFace and Semantic Kernel SDK.
You need to create a free account on Hugging Face and have a free HuggingFace access token to access the models.
Code Source Credits Microsoft Semantic Kernel Github Repository
Step 1: Install semantic-kernel for Python
!python -m pip install semantic-kernel==0.9.6b1
Step 2: Install other required libraries
!pip install transformers sentence_transformers accelerate huggingface_hub
Step 3: Import the required libraries
from semantic_kernel import Kernel
from semantic_kernel.memory.semantic_text_memory import SemanticTextMemory
from semantic_kernel.connectors.ai.hugging_face import HuggingFaceTextCompletion, HuggingFaceTextEmbedding
from semantic_kernel.core_plugins import TextMemoryPlugin
from semantic_kernel.memory import SemanticTextMemory, VolatileMemoryStore
Step 4: Let us create a Semantic Kernel using Semantic Kernel library
kernel = Kernel()#create a Kernel object
text_service_id = "openai-community/gpt2" #specify the LLM to use for text generation
#Let us add this LLM to our kernel object
#Since we are using Hugging Face model, we have imported and will use HuggingFaceTextCompletion class
#Below we have added text generation model to our kernel
kernel.add_service(
service=HuggingFaceTextCompletion(
service_id=text_service_id, ai_model_id=text_service_id, task="text-generation"
),
)
#Next we have added an embedding model from HF to our kernel
embed_service_id = "sentence-transformers/all-MiniLM-L6-v2"
embedding_svc = HuggingFaceTextEmbedding(service_id=embed_service_id, ai_model_id=embed_service_id)
kernel.add_service(
service=embedding_svc,
)
#Next we are adding volatile memory plugin to our kernel
memory = SemanticTextMemory(storage=VolatileMemoryStore(), embeddings_generator=embedding_svc)
kernel.add_plugin(TextMemoryPlugin(memory), "TextMemoryPlugin")
Step 5: Now that our kernel is created and plugins added to it, let us create a prompt template, set the configuation values for our text generation and create a custom function which can use the output of the LLM.
#imports
from semantic_kernel.connectors.ai.hugging_face import HuggingFacePromptExecutionSettings
from semantic_kernel.prompt_template import PromptTemplateConfig
#let us create a collection to store 5 pieces of information in memory plugin
#this is infomration about 5 animals
collection_id = "generic"
await memory.save_information(collection=collection_id, id="info1", text="Sharks are fish.")
await memory.save_information(collection=collection_id, id="info2", text="Whales are mammals.")
await memory.save_information(collection=collection_id, id="info3", text="Penguins are birds.")
await memory.save_information(collection=collection_id, id="info4", text="Dolphins are mammals.")
await memory.save_information(collection=collection_id, id="info5", text="Flies are insects.")
Step 6: Let us define a prompt template, this prompt template asks the LLM to recall the information about animals stored in Text Memory Plugin
# Define prompt function using SK prompt template language
my_prompt = """I know these animal facts:
- {{recall 'fact about sharks'}}
- {{recall 'fact about whales'}}
- {{recall 'fact about penguins'}}
- {{recall 'fact about dolphins'}}
- {{recall 'fact about flies'}}
Now, tell me something about: {{$request}}"""
Step 7: Next, we set the execution settings for the kernel, i.e., the LLM model and its configuration settings, the prompt template configuation and finally we create a semantic function called my_function and add it to the kernel.
#execution settings for AI model
execution_settings = HuggingFacePromptExecutionSettings(
service_id=text_service_id,
ai_model_id=text_service_id,
max_tokens=200,
eos_token_id=2,
pad_token_id=0,
max_new_tokens = 100,
)
#prompt template configurations
prompt_template_config = PromptTemplateConfig(
template=my_prompt,
name="text_complete",
template_format="semantic-kernel",
execution_settings=execution_settings,
)
#let the semantic function to the kernel
# this function uses above prompt and model
my_function = kernel.add_function(
function_name="text_complete",
plugin_name="TextCompletionPlugin",
prompt_template_config=prompt_template_config,
)
Step 8: Let us invoke the function using the kernel object:
output = await kernel.invoke(
my_function,
request="What are whales?",
)
Step 9: Display the output:
output = str(output).strip()
query_result1 = await memory.search(
collection=collection_id, query="What are sharks?", limit=1, min_relevance_score=0.3
)
print(f"The queried result for 'What are sharks?' is {query_result1[0].text}")
print(f"{text_service_id} completed prompt with: '{output}'")
Now, let us use a different prompt for a chat conversation. This prompt allows you to have a conversation with LLM, it maintains the history of your conversation.
You should have import the required libraries as shown above:
Create the prompt template:
#Source: https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/04-kernel-arguments-chat.ipynb
prompt = """
ChatBot can have a conversation with you about any topic.
It can give explicit instructions or say 'I don't know' if it does not have an answer.
{{$history}}
User: {{$user_input}}
ChatBot: """
Create prompt template configuration and a semantic function
#Source: #https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/04-kernel-arguments-chat.ipynb
#{{$user_input}} is used as a variable to hold user input
#{{$history}} is used as a variable to hold previous conversation history
#Register your semantic function
from semantic_kernel.prompt_template.input_variable import InputVariable
prompt = """
ChatBot can have a conversation with you about any topic.
It can give explicit instructions or say 'I don't know' if it does not have an answer.
\n
{{$history}}
\n
User: {{$user_input}}
\n
ChatBot: """
execution_settings = HuggingFacePromptExecutionSettings(
service_id=text_service_id,
ai_model_id=text_service_id,
max_tokens=100,
eos_token_id=2,
pad_token_id=0,
max_new_tokens = 50,
)
prompt_template_config = PromptTemplateConfig(
template=prompt,
name="chat",
template_format="semantic-kernel",
input_variables = [
InputVariable(name="user_input", description="The user input", is_required=True),
InputVariable(name="history", description="The conversation history", is_required=True),
],
execution_settings=execution_settings,
)
chat_function = kernel.add_function(
function_name="chat",
plugin_name="chatPlugin",
prompt_template_config=prompt_template_config,
)
Create a ChatHistory object, and add system instruction to it.
from semantic_kernel.contents import ChatHistory
chat_history = ChatHistory()
chat_history.add_system_message("You are a helpful chatbot.")
Create a KernelArguments object to pass the user input to the chatbot:
from semantic_kernel.functions import KernelArguments
arguments = KernelArguments(user_input="Tell me about wild animals", history=chat_history)
Wait for the response and print it
response = await kernel.invoke(chat_function, arguments)
print(response)
You will see some output like this:
ChatBot can have a conversation with you about any topic.
It can give explicit instructions or say 'I don't know' if it does not have an answer.
<chat_history><message role="system">You are a helpful chatbot.</message></chat_history>
User: Tell me about wild animals
ChatBot: 【My name is Alex W, I am the chief of the Animal World Wildlife Trust. You can find animal videos here: http://www.evilswild.org/gameplay/wild-animals/>
<chat_history>
Now, let us update history of the chatbot
#Update the history with the output
chat_history.add_assistant_message(str(response))
Next, let us define a function for continuously chatting with the bot
#Keep Chatting
async def chat(input_text: str) -> None:
# Save new message in the context variables
print(f"User: {input_text}")
# Process the user message and get an answer
answer = await kernel.invoke(chat_function, KernelArguments(user_input=input_text, history=chat_history))
# Show the response
print(f"ChatBot: {answer}")
chat_history.add_user_message(input_text)
chat_history.add_assistant_message(str(answer))
After defininig above function, you can call it again and again
await chat("I love Gorillas, what do you say?")
await chat("Tell me about sea horses")
To print the entire chat history:
print(chat_history)
Creating your own functions to work with LLM
You should have imported all the required libraries. Below is a function to generate a random number between 3 and 8. We will pass this randomly generated number to the LLM and tell it to generate these many paragraphs of text for a story.
#Code source: https://github.com/microsoft/semantic-kernel/blob/main/python/notebooks/08-native-function-inline.ipynb
import random
from semantic_kernel.functions import kernel_function
class GenerateNumberPlugin:
"""
Description: Generate a number between 3-x.
"""
@kernel_function(
description="Generate a random number between 3-x",
name="GenerateNumberThreeOrHigher",
)
def generate_number_three_or_higher(self, input: str) -> str:
"""
Generate a number between 3-<input>
Example:
"8" => rand(3,8)
Args:
input -- The upper limit for the random number generation
Returns:
int value
"""
try:
return str(random.randint(3, int(input)))
except ValueError as e:
print(f"Invalid input {input}")
raise e
Next, let’s create a semantic function that accepts a number as {{input}} and generates that number of paragraphs in a story about two Corgis on an adventure. input is a default variable semantic functions can use. This input is the random number generated by above function.
from semantic_kernel.connectors.ai.hugging_face import HuggingFacePromptExecutionSettings
from semantic_kernel.prompt_template import PromptTemplateConfig, InputVariable
prompt = """
Write a short story about two Corgis on an adventure.
The story must be:
- G rated
- Have a positive message
- No sexism, racism or other bias/bigotry
- Be exactly {{$input}} paragraphs long. It must be this length.
"""
execution_settings = HuggingFacePromptExecutionSettings(
service_id=text_service_id,
ai_model_id=text_service_id,
max_tokens=300,
eos_token_id=2,
pad_token_id=0,
max_new_tokens = 50,
)
prompt_template_config = PromptTemplateConfig(
template=prompt,
name="story",
template_format="semantic-kernel",
input_variables=[
InputVariable(name="input", description="The user input", is_required=True),
],
execution_settings=execution_settings,
)
corgi_story = kernel.add_function(
function_name="CorgiStory",
plugin_name="CorgiPlugin",
prompt_template_config=prompt_template_config,
)
generate_number_plugin = kernel.add_plugin(GenerateNumberPlugin(), "GenerateNumberPlugin")
Let us now generate the paragraph count by running the random number generator function.
#Let's generate a paragraph count.
# Run the number generator
generate_number_three_or_higher = generate_number_plugin["GenerateNumberThreeOrHigher"]
number_result = await generate_number_three_or_higher(kernel, input=6)
print(number_result)
Let us invoke the function
story = await corgi_story.invoke(kernel, input=number_result.value)
Print the output:
print(f"Generating a corgi story exactly {number_result.value} paragraphs long.")
print("=====================================================")
print(story)
This is just the beginning. Go ahead and explore the examples and possibilities at the original documention.

